Pernah nggak kamu sudah sampai tahap olah data, regresi sudah jalan, tabel SPSS sudah keluar, tapi dosen malah berhenti di satu titik yang rasanya “loh, kok balik lagi ke sini?” yaitu uji asumsi klasik? Padahal di kepala kamu mungkin yang penting hasil regresi keluar, nilai signifikansi ada, lalu tinggal masuk ke pembahasan. Masalahnya, dalam penelitian kuantitatif, khususnya regresi linear, bagian asumsi regresi seperti uji normalitas, multikolinearitas, dan heteroskedastisitas memang dipakai buat mengecek apakah model layak dibaca lebih lanjut. Tanpa pemeriksaan asumsi yang memadai, hasil regresi bisa menyesatkan atau minimal harus dibaca dengan sangat hati-hati.
Di sinilah banyak mahasiswa mulai kena revisi. Bukan karena nggak bisa klik menu di SPSS, tapi karena belum paham logika dasarnya. Ada yang hafal nama uji, tapi bingung saat diminta menjelaskan kenapa uji itu dilakukan. Ada yang tahu harus cek normalitas, tapi nggak paham apa yang sebenarnya sedang diperiksa. Ada juga yang menjalankan semua uji secara otomatis, lalu menuliskannya seperti daftar formalitas tanpa benar-benar menghubungkannya ke kelayakan model. Akibatnya, bagian ini kelihatan ada, tapi terasa kosong secara makna.
Padahal dosen biasanya justru melihat bagian ini sebagai titik penting. Mereka ingin tahu satu hal sederhana tapi krusial: model regresi yang kamu pakai itu sehat atau tidak? Dan jawaban atas pertanyaan itu memang sering dimulai dari uji asumsi klasik. Jadi kalau bagian ini terasa lemah, dosen biasanya langsung curiga bahwa proses olah datanya belum benar-benar matang, meskipun tabel hasil utama sudah kelihatan rapi.
Kalau kamu sudah sampai tahap regresi, uji asumsi klasik, atau membaca output SPSS tapi masih bingung menentukan langkah yang benar, kamu bisa memakai bimbingan olah data agar proses analisis dan interpretasi hasil lebih terarah.
Artikel ini akan membahas uji asumsi klasik dengan cara yang lebih santai tapi tetap runtut. Kita nggak akan melihatnya sebagai kumpulan istilah teknis yang harus dihafal, tapi sebagai logika dasar yang membantu kamu memastikan model regresi tidak dibaca secara serampangan. Fokusnya bukan sekadar tahu nama uji, tapi paham kenapa uji itu dilakukan dan bagaimana menuliskannya dengan lebih waras di Bab 4.
Di bagian pertama ini, kita mulai dari fondasinya dulu: kenapa uji asumsi klasik hampir selalu ditanya dosen, lalu apa sebenarnya maksud uji ini dalam hubungan dengan regresi. Kalau fondasi ini sudah kebentuk, bagian teknis seperti membaca hasil uji normalitas, multikolinearitas, dan heteroskedastisitas nanti akan jauh lebih gampang masuk ke kepala.
Daftar Isi
ToggleKenapa Uji Asumsi Klasik Selalu Ditanya Dosen?
Kalau kamu pakai analisis regresi, dosen hampir pasti akan menanyakan satu hal yang sama: model yang kamu gunakan itu layak atau tidak? Nah, salah satu pintu awal untuk menjawab pertanyaan itu memang ada di uji asumsi klasik. Dalam regresi linear, pemeriksaan asumsi dipakai untuk melihat apakah data dan model cukup memenuhi syarat dasar sehingga hasil estimasi dan pengujian lanjutannya tidak menyesatkan. Jadi dosen menanyakan bagian ini bukan untuk mempersulit, tapi karena mereka ingin tahu apakah kamu paham pondasi model yang kamu pakai.
Masalahnya, banyak mahasiswa terlalu cepat masuk ke hasil utama. Begitu nilai uji t atau uji F sudah muncul dan terlihat signifikan, langsung merasa aman. Padahal dosen biasanya melihat satu langkah ke belakang: sebelum bicara hasil, modelnya sendiri sudah dicek belum? Karena kalau ada masalah di asumsi dasar, hasil regresi bisa jadi kurang stabil, kurang akurat, atau perlu dibaca dengan kehati-hatian ekstra.
Selain itu, bagian ini juga sering dipakai dosen untuk membaca tingkat pemahaman metodologis mahasiswa. Mahasiswa yang benar-benar paham asumsi regresi biasanya nggak cuma tahu nama uji, tapi tahu fungsi masing-masing uji dan tahu kenapa hasilnya penting. Sebaliknya, kalau seseorang hanya menyalin template “data normal”, “tidak terjadi multikolinearitas”, dan “tidak terjadi heteroskedastisitas” tanpa bisa menjelaskan maknanya, dosen biasanya cepat sadar bahwa bagian ini dikerjakan setengah hati.
Dari sudut pandang penulisan skripsi, uji asumsi klasik juga penting karena dia membantu menjaga logika Bab 4. Hasil regresi yang kelihatannya bagus bisa terasa goyah kalau tidak didahului pemeriksaan model yang cukup sehat. Jadi bagian ini sebenarnya bukan penghambat sebelum hasil, tapi semacam pagar pengaman supaya hasil utama nggak dibaca asal cepat.
Itulah kenapa dosen hampir selalu kembali ke bagian ini. Bukan karena mereka suka memutar proses, tapi karena mereka ingin memastikan bahwa pembahasan regresimu berdiri di atas fondasi yang cukup rapi. Dalam konteks skripsi, itu penting banget. Karena penelitian yang kelihatan “jalan” belum tentu benar-benar “aman” kalau pondasi modelnya nggak diperiksa dengan serius.
Apa Itu Uji Asumsi Klasik dan Hubungannya dengan Regresi?
Secara sederhana, uji asumsi klasik adalah serangkaian pengujian untuk melihat apakah model regresi linear memenuhi syarat dasar tertentu sehingga hasil analisisnya layak digunakan. Bahasa gampangnya begini: regresi itu bukan cuma soal memasukkan variabel X dan Y lalu menunggu output keluar. Ada kondisi-kondisi yang perlu dicek dulu supaya modelnya nggak bermasalah secara dasar. Pemeriksaan itulah yang biasanya disebut sebagai uji asumsi klasik.
Dalam praktik skripsi, istilah asumsi regresi paling sering muncul saat mahasiswa memakai regresi linear sederhana atau regresi linear berganda. Uji yang paling umum dibahas biasanya uji normalitas, multikolinearitas, dan heteroskedastisitas. Ketiganya dipakai untuk membaca sisi yang berbeda dari kelayakan model: apakah residual cukup wajar untuk inferensi, apakah variabel bebas terlalu saling bertumpuk, dan apakah sebaran error cukup stabil.
Hubungan antara uji asumsi klasik dan regresi sangat dekat, karena regresi tidak cuma ingin menghasilkan angka koefisien, tapi juga ingin menghasilkan pembacaan yang masuk akal dan bisa dipertanggungjawabkan. Kalau modelnya punya gangguan dasar yang serius, hasil uji t, uji F, dan koefisien regresi bisa jadi lebih rentan menyesatkan. Karena itu, asumsi ini bukan tambahan kosmetik. Dia bagian dari proses memastikan bahwa model yang sedang kamu pakai cukup sehat untuk dibahas.
Hal yang juga penting dipahami adalah tidak semua uji harus dipaksakan dengan cara yang sama di semua penelitian. Misalnya, autokorelasi sangat berkaitan dengan error yang saling berhubungan karena unsur waktu, sehingga isu ini biasanya lebih menonjol pada data yang punya komponen temporal atau runtut waktu. Jadi, semakin kamu paham jenis data dan model yang dipakai, semakin masuk akal juga keputusanmu soal uji mana yang relevan dan bagaimana membacanya.
Jadi kalau mau diringkas, uji asumsi klasik itu bukan daftar ritual sebelum regresi. Ia adalah cara untuk memastikan bahwa model regresi yang kamu jalankan tidak dibaca secara sembrono. Dan justru karena fungsinya sedekat itu dengan kualitas hasil, bagian ini nggak bisa diperlakukan sebagai formalitas yang cukup diisi dengan template. Harus dipahami, harus dibaca, dan harus bisa dijelaskan.
Kapan Uji Asumsi Klasik Dipakai dan Kapan Tidak Perlu Dipaksakan?
Kalau kamu memakai regresi linear, terutama regresi linear berganda, maka uji asumsi klasik memang sangat umum dipakai. Alasannya sederhana: model regresi linear punya beberapa syarat dasar yang perlu diperiksa supaya hasil estimasi dan pengujian lanjutan tidak dibaca sembarangan. Dalam konteks ini, pemeriksaan seperti uji normalitas, multikolinearitas, dan heteroskedastisitas memang relevan karena berkaitan langsung dengan kesehatan model regresi.
Masalahnya, banyak mahasiswa memakai logika yang terlalu mekanis. Begitu dengar kata regresi, semua uji langsung dijalankan tanpa berpikir apakah semuanya memang relevan dengan model dan karakter datanya. Padahal pendekatan yang lebih matang justru dimulai dari satu pertanyaan: saya sedang pakai model apa, datanya seperti apa, dan asumsi mana yang memang penting untuk dicek? Kalau pertanyaan ini jelas, kamu nggak akan lagi menjalankan uji hanya karena “di contoh skripsi biasanya begitu.”
Untuk penelitian dengan data cross-section, misalnya data mahasiswa, pelanggan, pegawai, atau responden survei pada satu periode waktu, pembahasan paling umum memang biasanya fokus pada uji normalitas, multikolinearitas, dan heteroskedastisitas. Sementara autokorelasi lebih sering dibahas ketika data punya unsur urutan waktu atau runtut waktu, karena autokorelasi berkaitan dengan keterhubungan error antarperiode. Jadi kalau datamu bukan time series, kamu tidak harus otomatis memaksakan pembahasan autokorelasi hanya demi terlihat lengkap.
Nah, ini penting banget buat kamu pegang: penelitian yang matang bukan penelitian yang paling banyak uji, tapi penelitian yang paling paham kenapa uji tertentu dipakai. Dosen biasanya jauh lebih menghargai mahasiswa yang bisa menjelaskan alasan metodologis dengan jernih dibanding mahasiswa yang cuma menjalankan semua prosedur lalu menuliskannya seperti daftar belanja statistik. Jadi, jangan pakai logika “yang penting semua ada”. Pakai logika “yang dipakai harus relevan.”
Kalau kamu sudah sampai tahap ini, berarti kamu mulai masuk ke cara berpikir yang lebih aman. Karena inti dari asumsi regresi bukan sekadar kelengkapan Bab 4, tapi memastikan bahwa model yang kamu pakai memang cukup sehat untuk dilanjutkan ke pembacaan hasil utama. Dan itu jauh lebih penting daripada sekadar punya banyak tabel di lampiran.
Masalah Paling Umum Saat Mahasiswa Mengerjakan Uji Asumsi Klasik
1. Mahasiswa tahu nama uji, tapi nggak paham fungsi uji
Ini pola masalah yang paling sering muncul. Banyak mahasiswa hafal nama-namanya: uji normalitas, multikolinearitas, heteroskedastisitas. Tapi saat ditanya, “kenapa uji ini dilakukan?” jawabannya masih mengambang. Mereka tahu harus ada, tapi belum tentu tahu untuk apa.
Akibatnya, bagian uji asumsi klasik sering terasa seperti formalitas. Tabel ditampilkan, hasil ditulis, lalu selesai. Tidak ada hubungan yang jelas antara hasil uji dengan kelayakan model regresi. Padahal justru di situlah makna utamanya. Uji asumsi bukan sekadar checkpoint administratif, tapi pemeriksaan apakah model layak dibaca lebih lanjut.
Kalau fungsi uji tidak dipahami, mahasiswa juga jadi lebih gampang salah saat menjelaskan hasil. Misalnya membahas normalitas seolah-olah itu langsung bicara pengaruh antarvariabel, padahal bukan itu perannya. Atau menulis “tidak terjadi multikolinearitas” tanpa bisa menjelaskan kenapa kondisi itu penting buat regresi berganda. Hasilnya, Bab 4 terasa ada, tapi dosen tetap melihatnya setengah matang.
Masalah seperti ini sebenarnya bukan karena mahasiswa tidak belajar, tapi karena proses belajarnya terlalu dekat ke template dan terlalu jauh dari logika. Mereka mengingat urutan uji, tapi belum benar-benar menangkap fungsi masing-masing uji dalam model.
Jadi, kalau kamu mau aman, mulai biasakan diri bertanya fungsi sebelum membaca hasil. Karena dari situlah kualitas pembahasanmu akan kelihatan.
2. Hasil dibaca mentah: “lulus” atau “tidak lulus” tanpa makna
Masalah kedua adalah hasil uji dibaca terlalu mentah. Banyak mahasiswa melihat angka, lalu langsung memberi label: normal atau tidak normal, ada atau tidak ada multikolinearitas, ada atau tidak ada heteroskedastisitas. Selesai. Padahal itu baru tahap pengamatan, belum benar-benar interpretasi.
Dalam skripsi, dosen biasanya nggak cukup puas dengan label “lolos” atau “tidak lolos”. Mereka ingin tahu apa arti hasil itu untuk model regresi yang kamu pakai. Misalnya kalau hasil normalitas mendukung distribusi residual yang wajar, berarti model punya dasar inferensi yang lebih layak. Kalau tidak ada multikolinearitas, berarti variabel bebas masih bisa dibaca kontribusinya dengan lebih jernih. Kalau tidak ada heteroskedastisitas, berarti sebaran residual relatif stabil. Nah, bagian makna seperti ini yang sering hilang.
Ketika hasil dibaca terlalu mentah, Bab 4 jadi terasa seperti daftar status: aman, aman, aman. Tapi tidak ada alur berpikir yang menunjukkan kenapa status itu penting. Ini membuat pembahasan terasa kering dan sangat mudah dianggap template.
Padahal, dalam uji asumsi klasik, yang dicari bukan sekadar daftar kelulusan, tapi gambaran apakah modelmu cukup sehat untuk diuji lebih lanjut. Jadi narasinya harus bergerak ke sana, bukan berhenti di angka.
Semakin kamu bisa mengubah hasil jadi makna, semakin kuat juga pembacaan metodologismu.
3. Tiap uji dibahas terpisah, tapi tidak disambungkan ke kelayakan model
Ini juga masalah yang sering bikin bagian asumsi terlihat “ada tapi nggak nyambung”. Mahasiswa membahas uji normalitas di satu subbagian, lalu multikolinearitas di subbagian lain, lalu heteroskedastisitas di bagian berikutnya. Tapi setelah semua selesai, tidak ada simpulan yang menyatukan ketiganya.
Padahal inti dari uji asumsi klasik adalah melihat model secara keseluruhan. Artinya, hasil tiap uji tidak seharusnya berhenti sebagai potongan pembahasan yang berdiri sendiri. Hasil-hasil itu harus dikumpulkan lagi ke satu kesimpulan: apakah model regresi layak digunakan untuk pengujian hipotesis atau tidak.
Kalau simpulan seperti ini tidak ditulis, pembaca akan merasa asumsi-asumsi itu cuma ditempel satu-satu tanpa arah. Dan dosen biasanya cukup peka terhadap hal seperti ini. Mereka ingin lihat bahwa kamu paham hubungan antarbagian, bukan sekadar tahu urutan subjudulnya.
Jadi setelah membahas satu per satu, biasakan tutup dengan satu kalimat penghubung. Misalnya bahwa secara umum model tidak menunjukkan pelanggaran asumsi yang berarti, sehingga regresi dapat dilanjutkan. Kalimat sederhana seperti ini sangat membantu.
Karena pada akhirnya, yang diuji bukan tabel per tabel, tapi kesehatan modelmu sebagai satu kesatuan.
4. Logika uji sering tercampur dengan logika hipotesis
Ini kesalahan yang kelihatannya kecil tapi sebenarnya sangat sering terjadi. Mahasiswa kadang membaca hasil uji asumsi klasik dengan cara yang mirip saat membaca hasil uji hipotesis. Jadi semua hal terasa seperti pengaruh, signifikan, atau tidak signifikan. Padahal fungsi keduanya berbeda.
Asumsi regresi dipakai untuk memeriksa kondisi model. Sementara uji hipotesis dipakai untuk menjawab dugaan hubungan atau pengaruh antarvariabel. Kalau dua logika ini tercampur, pembahasan jadi gampang kacau. Misalnya normalitas dibahas seolah-olah itu membuktikan adanya pengaruh. Atau heteroskedastisitas diperlakukan seolah-olah setara dengan hasil uji t.
Masalah seperti ini sering muncul karena mahasiswa terlalu terburu-buru ingin masuk ke hasil utama. Akhirnya semua output dibaca dengan cara yang sama: cari angka, lihat batas tertentu, lalu simpulkan. Padahal dalam regresi, setiap bagian punya peran yang berbeda.
Kalau kamu bisa membedakan logika pemeriksaan model dan logika pengujian hipotesis, pembahasanmu akan terasa jauh lebih rapi. Dosen juga lebih mudah melihat bahwa kamu paham struktur analisis, bukan sekadar mengikuti langkah-langkah prosedural.
Jadi, sebelum menulis hasil, biasakan tanya: ini sedang memeriksa model atau sedang menjawab hipotesis? Pertanyaan kecil itu sangat membantu menjaga arah pembahasan.
5. Terlalu panik saat satu hasil tidak ideal
Ini masalah yang sangat manusiawi, tapi tetap perlu dibenahi. Banyak mahasiswa langsung down kalau satu hasil asumsi tidak seideal yang dibayangkan. Misalnya hasil normalitas kurang meyakinkan, atau ada gejala tertentu di heteroskedastisitas. Reaksi yang muncul biasanya dua: panik total atau menutup mata.
Padahal tidak semua masalah di asumsi regresi otomatis berarti penelitian gagal. Dalam banyak kasus, yang dibutuhkan justru pembacaan yang lebih hati-hati, evaluasi model yang lebih jujur, dan penjelasan yang lebih matang. Jadi, respons terbaik bukan panik, tapi memahami dulu seberapa besar masalahnya dan apa implikasinya.
Masalahnya, karena banyak mahasiswa terbiasa melihat asumsi secara hitam-putih, begitu ada satu bagian yang kurang ideal, mereka langsung merasa semua hasil regresi nggak bisa dipakai. Padahal dunia penelitian jarang sesederhana itu. Ada kondisi yang memang perlu perbaikan, ada kondisi yang cukup diberi catatan, dan ada juga kondisi yang masih bisa dijelaskan secara metodologis.
Dosen biasanya lebih menghargai mahasiswa yang jujur dan paham keterbatasan model dibanding yang memaksa semua terlihat sempurna. Jadi kalau ada hasil yang kurang ideal, jangan langsung panik. Baca lagi logikanya. Cek lagi konteks datanya. Baru ambil sikap.
Karena sering kali, yang bikin Bab 4 balik lagi bukan hasil yang kurang ideal itu sendiri, tapi cara panik membacanya.
Uji Asumsi Klasik: 7 Urutan Biar Nggak Salah
Nah, sekarang masuk ke bagian yang paling praktis. Setelah paham kenapa uji asumsi klasik selalu ditanya dosen, tahu hubungannya dengan asumsi regresi, dan mulai kebayang kapan uji itu relevan dipakai, sekarang pertanyaannya tinggal satu: urutan amannya gimana? Karena jujur, banyak revisi itu bukan muncul karena mahasiswa nggak tahu nama uji, tapi karena cara ngerjainnya lompat-lompat, baca hasilnya mentah, dan nggak menghubungkannya ke kelayakan model. Dalam diagnostik regresi, inti pemeriksaannya memang bukan sekadar “punya tabel”, tapi memastikan model cukup layak sebelum hasil utamanya dibahas.
1. Pahami dulu model dan jenis data yang dipakai
Sebelum menjalankan uji apa pun, kamu harus paham dulu model analisis dan jenis data yang sedang kamu pakai. Ini kelihatannya dasar banget, tapi justru paling sering dilompati. Banyak mahasiswa langsung buka SPSS, jalankan regresi, lalu otomatis lanjut ke semua uji yang pernah mereka lihat di skripsi orang lain. Padahal pendekatan yang lebih sehat itu harus dimulai dari satu hal: saya pakai regresi linear apa, dan data saya karakteristiknya seperti apa? Dalam diagnostik regresi, jenis model dan karakter data memang menentukan asumsi mana yang lebih relevan untuk diperiksa.
Kalau kamu pakai regresi linear berganda pada data cross-section, maka pembahasan yang paling umum memang biasanya fokus ke uji normalitas, multikolinearitas, dan heteroskedastisitas. Tapi kalau kamu sedang bekerja dengan data yang punya unsur waktu, isu independensi error atau autokorelasi bisa jadi lebih relevan. Jadi dari awal kamu harus sadar bahwa asumsi regresi itu bukan daftar wajib yang disalin mentah, tapi rangkaian pemeriksaan yang dipilih berdasarkan model.
Masalah besar muncul ketika mahasiswa tidak membangun kesadaran ini. Akibatnya, semua uji dikerjakan seperti ritual. Ada tabelnya, ada kalimatnya, tapi tidak ada logika yang mengikat semuanya. Dosen biasanya cepat menangkap bagian ini, karena pembahasan yang terlalu template terasa “jalan”, tapi nggak benar-benar menunjukkan pemahaman metodologis.
Jadi langkah pertama yang paling aman adalah berhenti sebentar sebelum buka output. Tanyakan: model saya ini model apa, datanya seperti apa, dan pemeriksaan apa yang memang masuk akal buat model ini? Pertanyaan ini sederhana, tapi justru jadi penentu apakah bagian uji asumsi klasik kamu nanti terasa hidup atau terasa tempelan.
Kalau fondasi ini sudah jelas, langkah-langkah sesudahnya akan jauh lebih tenang. Karena kamu tidak lagi bekerja dengan logika “yang penting lengkap”, tapi dengan logika “yang saya pakai memang relevan”. Dan itu jauh lebih kuat di mata dosen.
2. Kerjakan uji normalitas dengan tujuan yang jelas
Setelah model dan data dipahami, langkah berikutnya yang paling sering dibahas adalah uji normalitas. Dalam konteks regresi, yang diperhatikan secara ideal adalah normalitas error atau residual, karena normalitas ini berkaitan terutama dengan validitas pengujian inferensial seperti uji t dan uji F, bukan semata-mata sekadar “data harus normal”. UCLA juga menekankan bahwa normalitas error dibutuhkan terutama agar pengujian statistiknya valid, sementara estimasi koefisien sendiri lebih langsung bergantung pada syarat lain tentang error.
Masalah yang paling sering terjadi adalah mahasiswa membaca uji normalitas terlalu dangkal. Begitu hasilnya terlihat aman, langsung ditulis “data berdistribusi normal”. Selesai. Padahal yang lebih penting adalah menjelaskan apa arti hasil itu untuk model regresi yang sedang dipakai. Jadi, jangan berhenti di label normal atau tidak normal. Jelaskan bahwa hasil tersebut menunjukkan residual model tidak menyimpang secara berarti dari distribusi yang diharapkan, sehingga model dapat dilanjutkan ke tahap pengujian berikutnya dengan lebih aman.
Di sisi lain, kamu juga perlu hati-hati supaya nggak membaca normalitas seperti membaca hipotesis. Normalitas bukan uji pengaruh. Dia tidak menjawab apakah X memengaruhi Y. Dia hanya membantu memeriksa apakah salah satu kondisi dasar model cukup wajar. Nah, kalau logika ini tidak dibedakan, pembahasan Bab 4 gampang tercampur dan terasa tidak dewasa secara metodologis.
Karena itu, saat menulis hasil uji normalitas, pakai kalimat yang menegaskan fungsi uji tersebut. Misalnya bahwa hasil pemeriksaan normalitas residual mendukung kelayakan model untuk dianalisis lebih lanjut. Kalimat seperti ini sederhana, tapi jauh lebih kuat daripada hanya menyalin status “normal” dari output.
Intinya, uji normalitas jangan diperlakukan sebagai formalitas pembuka. Dia memang bukan pusat hasil penelitian, tapi tetap punya peran penting dalam menunjukkan bahwa model regresi tidak dibaca secara serampangan.
3. Cek multikolinearitas sebelum menarik simpulan regresi
Kalau kamu pakai regresi berganda, maka multikolinearitas adalah salah satu bagian yang nggak boleh dibaca asal. Secara sederhana, multikolinearitas terjadi ketika prediktor terlalu kuat hubungannya satu sama lain, sehingga model jadi kesulitan membedakan kontribusi masing-masing variabel bebas. UCLA secara eksplisit menyebut bahwa collinearity atau multicollinearity bisa menimbulkan masalah dalam mengestimasi koefisien regresi.
Masalah yang sering terjadi adalah mahasiswa hafal patokan angka, tapi belum paham kenapa multikolinearitas itu penting. Padahal fungsi utama uji ini adalah memastikan bahwa tiap variabel bebas masih punya ruang yang cukup untuk dibaca kontribusinya dalam model. Kalau variabel bebas terlalu bertumpuk, koefisien bisa jadi kurang stabil, bahkan ketika model secara umum kelihatan baik.
Karena itu, pembahasan uji ini jangan berhenti di kalimat “tidak terjadi multikolinearitas”. Tambahkan maknanya. Misalnya bahwa model tidak menunjukkan gejala hubungan linear yang berlebihan antarvariabel independen, sehingga pembacaan kontribusi masing-masing prediktor dalam regresi dapat dilakukan dengan lebih tenang. Kalimat seperti ini menunjukkan bahwa kamu paham fungsi uji, bukan cuma hafal hasilnya.
Hal lain yang juga penting, multikolinearitas bukan berarti semua variabel harus benar-benar terpisah total. Dalam penelitian sosial, hubungan antarvariabel bebas itu kadang wajar. Yang menjadi masalah adalah ketika hubungan itu terlalu kuat sampai mengganggu estimasi. Jadi jangan membaca uji ini secara hitam-putih tanpa konteks.
Kalau kamu bisa menjelaskan multikolinearitas dengan logika seperti ini, dosen biasanya langsung melihat bahwa kamu ngerti model yang dipakai. Dan ini sangat membantu supaya bagian asumsi regresi kamu nggak terasa template.
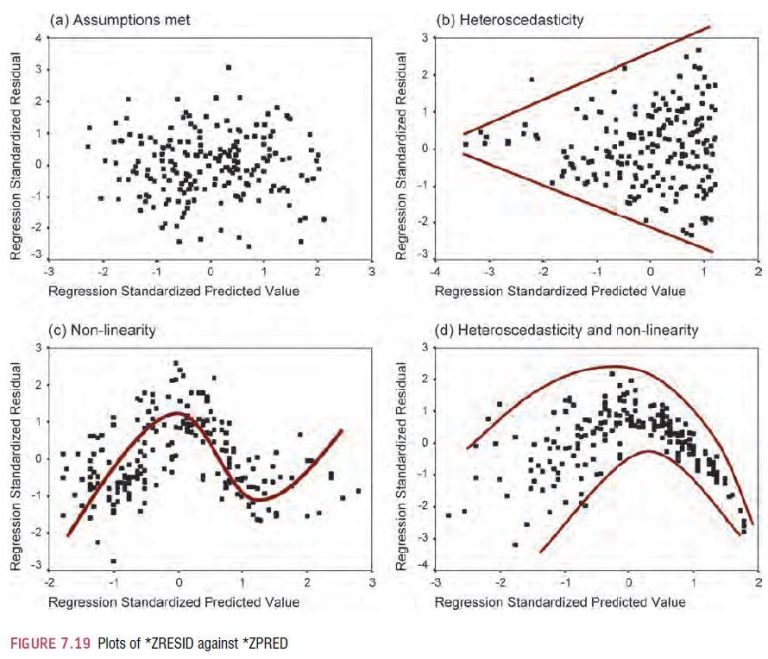
4. Uji heteroskedastisitas untuk melihat kestabilan error
Dalam uji asumsi klasik, bagian heteroskedastisitas juga sangat sering bikin mahasiswa bingung, biasanya karena istilahnya terdengar berat. Padahal kalau dijelaskan dengan bahasa lebih sederhana, inti uji ini adalah melihat apakah error atau residual model punya sebaran yang relatif konstan atau justru berubah-ubah. Dalam diagnostik regresi, kondisi ideal yang dicari adalah homoscedasticity, yaitu error variance yang konstan; kebalikannya, heteroscedasticity, bisa membuat interpretasi hasil perlu lebih hati-hati.
Yang sering bikin revisi adalah mahasiswa menjalankan uji heteroskedastisitas, lalu langsung copy kalimat template begitu hasilnya keluar. Misalnya, “tidak terjadi heteroskedastisitas.” Selesai. Padahal pembaca masih belum tahu kenapa kondisi itu penting. Fungsi utama uji ini justru untuk memberi gambaran apakah sebaran residual cukup stabil sehingga model lebih layak dipakai untuk pembacaan berikutnya.
Dalam penulisan yang lebih kuat, kamu bisa menjelaskan bahwa ketiadaan gejala heteroskedastisitas menunjukkan varians residual model relatif konstan, sehingga model regresi tidak menunjukkan masalah serius dari sisi kestabilan error. Narasi seperti ini lebih “hidup” karena menghubungkan hasil uji ke makna metodologisnya.
Selain itu, penting juga untuk tidak membaca uji ini seperti membaca pengaruh antarvariabel. Sama seperti normalitas dan multikolinearitas, heteroskedastisitas bukan menjawab hipotesis, tapi memeriksa kondisi model. Kalau logika ini nggak dibedakan, Bab 4 jadi gampang terlihat campur aduk.
Jadi, saat membahas uji ini, fokuskan narasi pada kestabilan residual dan kelayakan model. Jangan terlalu dekat ke bahasa software, tapi juga jangan terlalu umum sampai kehilangan makna. Titik tengahnya ada di penjelasan yang cukup ringkas, tapi tetap jelas hubungannya dengan model regresi.
5. Pahami bahwa tidak semua uji harus dipakai buta-buta
Ini salah satu titik yang paling membedakan penjelasan matang dan penjelasan template. Banyak mahasiswa merasa semakin banyak uji yang dijalankan, semakin ilmiah penelitiannya. Padahal belum tentu. Dalam regresi, yang lebih penting bukan kuantitas uji, tapi relevansi uji dan kualitas penjelasannya. UCLA juga menekankan bahwa ada asumsi inti dan ada isu-isu lain yang memang penting, tetapi tetap harus dibaca dalam konteks model yang sedang dianalisis.
Misalnya, untuk banyak penelitian regresi linear dengan data cross-section, pembahasan utama memang sering fokus pada uji normalitas, multikolinearitas, dan heteroskedastisitas. Tapi itu bukan berarti semua jenis diagnostik lain harus selalu dipaksakan masuk, apalagi kalau kamu sendiri tidak benar-benar tahu relevansinya. Pendekatan seperti itu justru sering membuat Bab 4 kelihatan penuh, tapi kosong secara pemahaman.
Sikap metodologis yang lebih sehat adalah begini: pakai uji yang memang dibutuhkan untuk modelmu, lalu jelaskan kenapa uji itu dipakai. Kalau kamu bisa menjelaskan alasan relevansi sebuah uji, pembahasanmu akan terasa jauh lebih kuat daripada sekadar menunjukkan bahwa semua prosedur pernah dijalankan.
Dosen biasanya juga lebih menghargai mahasiswa yang bisa bilang, “Saya fokus pada pemeriksaan ini karena relevan untuk model regresi linear saya,” dibanding mahasiswa yang hanya menampilkan semua kemungkinan tabel tanpa penjelasan. Jadi, jangan bekerja dengan logika “yang penting lengkap”. Kerja dengan logika “yang saya pakai memang masuk akal”.
Di level skripsi, cara berpikir seperti ini sudah sangat membantu. Karena menunjukkan bahwa kamu tidak cuma tahu daftar uji, tapi juga tahu kenapa sebuah uji ada di tempatnya.
6. Tulis hasil dengan bahasa penelitian, bukan bahasa menu SPSS
Ini bagian yang kelihatannya sederhana, tapi sangat berpengaruh ke kualitas Bab 4. Banyak mahasiswa menulis hasil uji asumsi klasik terlalu dekat dengan bahasa software. Jadi narasinya kaku, seperti hasil salin-tempel menu dan output. Padahal skripsi yang kuat butuh bahasa penelitian, bukan bahasa mesin.
Contoh gaya yang terlalu kaku misalnya: “Berdasarkan output SPSS pada bagian collinearity statistics diperoleh nilai tolerance dan VIF memenuhi syarat.” Kalimat seperti ini terlalu teknis dan terlalu dekat ke software. Lebih enak kalau diubah jadi bahasa penelitian, misalnya: “Hasil uji multikolinearitas menunjukkan bahwa model tidak mengalami hubungan linear yang berlebihan antarvariabel independen, sehingga regresi dapat dilanjutkan.” Isinya tetap sama, tapi nuansanya jauh lebih ilmiah dan lebih mudah dibaca.
Hal yang sama juga berlaku untuk uji normalitas dan heteroskedastisitas. Jangan cuma menyebut lokasi output atau nama menu, tapi jelaskan fungsi hasil itu. Fokus pada makna, bukan prosedurnya. Pembaca skripsi tidak perlu diajak berjalan-jalan ke menu SPSS. Mereka perlu tahu apa arti hasil itu untuk modelmu.
Dalam banyak kasus, dosen justru lebih terkesan pada narasi yang sederhana tapi paham, dibanding narasi yang penuh istilah teknis tapi terasa kosong. Karena yang dinilai bukan seberapa hafal kamu terhadap tombol software, tapi seberapa paham kamu membaca hasilnya.
Jadi, saat menulis Bab 4, biasakan mengubah output menjadi kalimat penelitian yang hidup. Ini salah satu langkah kecil yang sangat efektif untuk mengurangi revisi.
7. Tutup dengan simpulan umum tentang kelayakan model
Ini langkah penutup yang sering banget dilupakan. Banyak mahasiswa membahas satu per satu hasil uji normalitas, multikolinearitas, dan heteroskedastisitas, lalu berhenti begitu saja. Padahal inti dari uji asumsi klasik bukan sekadar menunjukkan bahwa kamu sudah menjalankan beberapa tes, tapi menunjukkan apakah model regresimu secara umum layak digunakan.
Karena itu, setelah semua uji dibahas, kamu perlu menutupnya dengan simpulan umum. Misalnya bahwa berdasarkan hasil pengujian asumsi klasik, model regresi tidak menunjukkan pelanggaran yang berarti sehingga layak digunakan untuk pengujian hipotesis. Kalimat seperti ini penting karena menyatukan hasil-hasil yang sebelumnya terpisah.
Tanpa simpulan penutup seperti ini, pembahasan asumsi sering terasa seperti kumpulan tabel yang berdiri sendiri. Angkanya ada, uji-uji ada, tapi pembaca nggak benar-benar dibawa ke pesan utamanya. Dosen biasanya langsung merasa ada yang kurang. Bukan karena hasilnya salah, tapi karena alur berpikirnya tidak ditutup dengan rapi.
Simpulan umum juga membantu menghubungkan bagian asumsi ke bagian hasil utama. Jadi pembaca paham bahwa sesudah model dinilai cukup sehat, barulah analisis regresi dilanjutkan ke pengujian hipotesis. Inilah hubungan logis yang membuat Bab 4 terasa utuh.
Jadi jangan berhenti di hasil tiap uji. Selalu tutup dengan satu kesimpulan yang menjawab pertanyaan terbesar: model ini layak dibahas lebih lanjut atau tidak?
Contoh Urutan Membaca Hasil Uji Asumsi Klasik di Skripsi
Supaya lebih kebayang, urutan yang lebih aman biasanya begini. Pertama, jelaskan dulu bahwa sebelum pengujian hipotesis dilakukan, model regresi diperiksa melalui uji asumsi klasik. Ini memberi konteks ke pembaca bahwa bagian ini bukan sisipan, tapi fondasi sebelum hasil utama dibahas.
Kedua, masuk ke uji normalitas. Jelaskan hasilnya secara ringkas, lalu sambungkan dengan maknanya bagi residual atau kelayakan inferensi model. Jangan berhenti di status “normal”, tapi lanjutkan ke implikasinya untuk analisis regresi.
Ketiga, lanjut ke multikolinearitas. Terangkan bahwa uji ini dipakai untuk melihat apakah antarvariabel independen terlalu bertumpuk secara linear. Lalu simpulkan apakah model masih memberi ruang yang cukup untuk membaca kontribusi masing-masing variabel bebas.
Keempat, bahas heteroskedastisitas. Jelaskan bahwa tujuan uji ini adalah memeriksa kestabilan sebaran residual. Kalau tidak ditemukan gejala yang serius, kamu bisa menyampaikan bahwa model relatif stabil dari sisi error variance.
Kelima, tutup dengan simpulan umum. Di sinilah kamu menyatukan semua hasil tadi menjadi satu kalimat besar tentang kelayakan model regresi. Urutan seperti ini enak dibaca, logis, dan bikin dosen lebih gampang mengikuti alur pembahasanmu.
Kesalahan Uji Asumsi Klasik yang Paling Sering Bikin Revisi
Setelah paham urutan yang lebih aman, sekarang kita masuk ke bagian yang sering banget jadi sumber revisi: kesalahan yang kelihatannya kecil, tapi efeknya bikin dosen langsung menahan pembahasan hasil regresi. Banyak mahasiswa merasa sudah menjalankan uji asumsi klasik, tapi tetap kena revisi karena cara baca dan cara tulisnya belum matang. Jadi masalahnya bukan sekadar ada atau nggaknya tabel, tapi bagaimana tabel itu dipahami.
1. Salah fungsi uji
Ini salah satu kesalahan uji asumsi klasik yang paling sering muncul. Mahasiswa tahu nama uji, tapi tidak benar-benar paham apa yang diperiksa. Akibatnya, uji normalitas dibaca seperti uji pengaruh, multikolinearitas diperlakukan seperti bukti hubungan antarvariabel penelitian, dan heteroskedastisitas dibahas seolah-olah menjawab hipotesis utama.
Padahal tiap uji punya fungsi yang beda. Normalitas membantu membaca kewajaran distribusi residual. Multikolinearitas membantu melihat apakah variabel independen terlalu bertumpuk secara linear. Heteroskedastisitas membantu mengecek kestabilan varians error. Jadi semuanya bicara soal kesehatan model, bukan soal menerima atau menolak hipotesis pengaruh.
Kalau fungsi uji ini tertukar, narasi Bab 4 langsung terasa goyah. Dosen biasanya cepat menangkap ini karena alur pembahasan jadi tidak nyambung. Kamu terlihat tahu nama uji, tapi belum paham logika alatnya.
Karena itu, sebelum menulis hasil, selalu tanya: uji ini sedang memeriksa model atau menjawab hipotesis? Kalau jawabannya belum jelas, berarti pembahasanmu masih rawan salah arah.
Semakin jelas kamu membedakan fungsi tiap uji, semakin kecil risiko revisi yang sebenarnya bisa dihindari.
2. Narasi terlalu mentah dan terlalu dekat ke software
Kesalahan berikutnya adalah cara menulis yang terlalu kaku. Banyak mahasiswa menulis hasil uji asumsi klasik seperti sedang membacakan menu SPSS. Misalnya terlalu banyak menyebut nama output, nama tombol, atau struktur tabel, tapi tidak menjelaskan maknanya.
Contoh yang terlalu mentah seperti:
“Berdasarkan output SPSS diperoleh nilai tolerance dan VIF memenuhi syarat.”
Kalimat ini tidak sepenuhnya salah, tapi terasa terlalu dekat ke software dan terlalu jauh dari bahasa penelitian.
Yang lebih kuat adalah menjelaskan fungsi hasilnya. Misalnya:
“Hasil uji multikolinearitas menunjukkan bahwa model tidak mengalami hubungan linear yang berlebihan antarvariabel independen, sehingga regresi dapat dilanjutkan.”
Kalimat seperti ini lebih hidup. Pembaca langsung tahu hasilnya apa dan kenapa itu penting. Dalam skripsi, pergeseran dari bahasa software ke bahasa penelitian ini penting banget. Karena yang dinilai dosen bukan seberapa hafal kamu dengan menu, tapi seberapa paham kamu membaca hasilnya.
Jadi saat menulis asumsi regresi, fokuslah pada arti hasil, bukan nama tombol yang kamu klik.
3. Hasil tiap uji berdiri sendiri, tapi tidak pernah disimpulkan bersama
Ini juga sering banget terjadi. Mahasiswa membahas uji normalitas, lalu pindah ke multikolinearitas, lalu lanjut ke heteroskedastisitas, tapi berhenti begitu saja setelah semua subbagian selesai. Tidak ada simpulan umum tentang apakah model regresi layak digunakan atau tidak.
Padahal inti dari uji asumsi klasik adalah memeriksa model secara keseluruhan. Artinya, setelah semua uji dibahas, kamu perlu menyatukan hasilnya ke dalam satu simpulan besar. Misalnya bahwa model tidak menunjukkan pelanggaran asumsi yang berarti, sehingga dapat dilanjutkan ke pengujian hipotesis.
Kalau simpulan ini tidak ada, pembaca akan merasa hasil uji cuma numpuk satu-satu. Ada tabelnya, ada penjelasannya, tapi nggak ada narasi yang menyatukan. Dan ini yang sering bikin dosen bilang pembahasanmu masih kurang matang.
Sebenarnya ini gampang diperbaiki. Setelah semua subbagian selesai, cukup tambahkan satu paragraf simpulan mini yang menegaskan kondisi model. Ini sederhana, tapi efeknya besar banget untuk kerapian Bab 4.
Karena penelitian yang kuat bukan cuma punya banyak hasil, tapi juga tahu bagaimana menyatukan hasil itu jadi logika yang utuh.
4. Terlalu panik kalau ada hasil yang tidak ideal
Ini kesalahan yang sangat manusiawi, tapi tetap harus dikontrol. Banyak mahasiswa langsung drop kalau satu bagian dari asumsi regresi tidak seideal harapan. Misalnya hasil normalitas kurang meyakinkan, atau ada indikasi tertentu di uji heteroskedastisitas. Reaksi awalnya sering panik: merasa penelitian gagal, merasa regresi nggak bisa dipakai, atau langsung ingin bongkar semuanya.
Padahal, tidak semua hasil yang kurang ideal berarti penelitianmu otomatis hancur. Dalam banyak situasi, yang dibutuhkan justru pembacaan yang lebih hati-hati dan penjelasan yang lebih jujur. Ada hasil yang memang perlu evaluasi lebih lanjut, ada yang cukup diberi catatan, dan ada juga yang masih bisa dipertanggungjawabkan sesuai konteks model.
Masalahnya, kalau kamu terlalu panik, keputusan metodologismu jadi mudah berlebihan. Bisa terlalu cepat merasa model gagal, atau malah terlalu cepat menutupi kelemahan tanpa penjelasan yang jujur. Dua-duanya sama-sama tidak sehat.
Dosen biasanya lebih menghargai mahasiswa yang bisa membaca hasil dengan tenang daripada mahasiswa yang berusaha membuat semuanya terlihat sempurna. Karena di penelitian, kedewasaan justru sering kelihatan dari cara kamu membaca keterbatasan model.
Jadi kalau ada hasil yang tidak ideal, jangan langsung panik. Baca konteksnya. Cek lagi logikanya. Lalu jelaskan dengan jujur dan proporsional.
5. Menjalankan semua uji hanya demi terlihat lengkap
Ini jebakan terakhir yang juga sering bikin bagian ini terasa dangkal. Banyak mahasiswa berpikir semakin banyak uji yang dijalankan, semakin ilmiah penelitiannya. Akibatnya, semua jenis pemeriksaan dimasukkan, tapi tidak semuanya benar-benar dipahami atau relevan untuk model yang dipakai.
Padahal pembahasan yang matang bukan yang paling banyak uji, tapi yang paling masuk akal urutannya. Kalau datamu cross-section dan modelmu regresi linear biasa, lalu kamu memaksakan semua jenis uji tambahan tanpa paham relevansinya, hasilnya justru bikin pembahasan terasa seperti daftar formalitas.
Dosen biasanya bisa melihat ini. Mereka tahu kapan mahasiswa menulis karena paham, dan kapan menulis karena takut dianggap kurang lengkap. Jadi jangan buru-buru menambah semua jenis uji kalau kamu sendiri belum yakin kenapa uji itu ada.
Lebih baik fokus pada uji yang memang penting untuk modelmu, lalu jelaskan dengan kuat. Itu jauh lebih bernilai daripada banyak tabel yang hanya ditempel tanpa makna.
Dalam uji asumsi klasik, kualitas penjelasan hampir selalu lebih penting daripada kuantitas output.
Cara Menulis Uji Asumsi Klasik di Bab 4 Supaya Nggak Kaku
Kalau kamu ingin bagian ini terasa lebih rapi dan enak dibaca, kuncinya sederhana: jangan perlakukan tabel sebagai pusat cerita. Jadikan tabel sebagai sumber data, lalu kamu yang memberi makna. Jadi setelah tabel tampil, jangan ulang semua angkanya satu-satu. Pilih bagian yang relevan, lalu jelaskan fungsi dan implikasinya terhadap model.
Misalnya setelah membahas uji normalitas, kamu tidak perlu membacakan seluruh hasil output. Cukup ambil bagian yang penting, lalu jelaskan bahwa hasil tersebut menunjukkan residual model tidak menyimpang secara berarti sehingga model dapat dilanjutkan. Begitu juga untuk multikolinearitas dan heteroskedastisitas. Fokus pada makna, bukan pada detail teknis yang tidak perlu dibacakan ulang. (stats.oarc.ucla.edu)
Selain itu, kamu bisa membuat tiap subbagian punya pola yang konsisten. Misalnya mulai dari tujuan uji, lalu hasil singkat, lalu maknanya untuk model. Pola seperti ini bikin pembahasan lebih nyaman dibaca karena alurnya stabil. Pembaca tidak harus menebak-nebak tiap paragraf sedang menuju ke mana.
Trik kecil lain yang sangat membantu adalah menutup tiap subbagian dengan satu kalimat simpulan mini. Jadi misalnya setelah uji heteroskedastisitas, kamu tutup dengan kalimat bahwa model tidak menunjukkan gejala ketidakstabilan residual yang berarti. Kalimat seperti ini bikin transisi ke bagian berikutnya lebih halus.
Kalau bagian asumsi ditulis seperti ini, Bab 4 biasanya terasa lebih hidup. Tidak lagi seperti kumpulan hasil yang ditempel, tapi seperti analisis yang benar-benar dibaca oleh peneliti.
Dan ini sangat membantu mengurangi kesan bahwa kamu hanya menyalin template.
Checklist Sebelum Hasil Regresi Dikirim ke Dosen
Sebelum Bab 4 kamu kirim, cek dulu poin-poin ini dengan jujur. Checklist ini sederhana, tapi sangat berguna buat mencegah revisi yang sebenarnya bisa dihindari:
- Apakah kamu benar-benar paham fungsi tiap uji dalam uji asumsi klasik?
- Apakah hasil uji normalitas sudah ditulis dengan makna yang jelas, bukan cuma status lolos atau tidak?
- Apakah pembahasan multikolinearitas tidak berhenti di angka saja, tapi juga menjelaskan pengaruhnya terhadap pembacaan model?
- Apakah hasil heteroskedastisitas dikaitkan dengan kestabilan error dalam model regresi?
- Apakah semua asumsi regresi yang kamu bahas memang relevan dengan jenis model dan data penelitianmu?
- Apakah kamu sudah menghindari kesalahan uji asumsi klasik yang paling umum, seperti salah fungsi uji, narasi mentah, dan tidak adanya simpulan umum?
- Apakah ada simpulan akhir yang menegaskan bahwa model regresi layak atau perlu dibaca dengan kehati-hatian tertentu?
- Apakah bahasamu sudah berupa bahasa penelitian, bukan bahasa menu software?
Kalau sebagian besar jawabannya sudah “iya”, maka peluang kamu kena revisi di bagian asumsi biasanya jauh lebih kecil. Bukan karena Bab 4 jadi sempurna, tapi karena logikanya sudah lebih rapi dan lebih gampang dipertanggungjawabkan.
Pada akhirnya, uji asumsi klasik bukan bagian tempelan yang cuma ditulis supaya Bab 4 terlihat lengkap. Ia adalah cara untuk memastikan bahwa model regresi yang kamu pakai memang cukup layak dibaca dan dibahas. Ketika kamu paham fungsi uji normalitas, tahu kenapa multikolinearitas harus dicek, mengerti makna heteroskedastisitas, dan bisa menjelaskan semuanya dalam konteks asumsi regresi, maka bagian hasil penelitianmu akan terasa jauh lebih kuat. Kamu nggak cuma punya output, tapi juga punya logika.
Sebaliknya, kalau bagian ini cuma dikerjakan karena “memang biasanya ada”, dosen akan cepat menangkap bahwa model yang kamu pakai belum benar-benar kamu pahami. Dan ini yang sering bikin revisi muncul, bahkan sebelum pembahasan regresi utama masuk jauh. Jadi, jangan fokus pada banyaknya uji. Fokus pada relevansi, urutan, dan cara membacanya.
Kalau kamu sudah bisa melihat uji asumsi klasik sebagai fondasi model, bukan sebagai formalitas, proses olah data biasanya jadi jauh lebih tenang. Kamu akan lebih siap saat menulis Bab 4, lebih percaya diri saat menjelaskan model ke dosen, dan lebih kecil kemungkinan tersandung kesalahan uji asumsi klasik yang sebenarnya sangat bisa dicegah. Karena pada akhirnya, yang bikin penelitian aman bukan sekadar output yang lengkap, tapi kemampuan menjelaskan kenapa output itu penting dan apa artinya bagi model regresi yang kamu gunakan.